Aprendizaje por refuerzo - Parte 3 - Acrobot
Ivan Moreno, 09 December 2018
Hice que mi computadora aprendiera a controlar un acrobot para la última parte de la unidad. Solo hacía falta usar un método, pero me emocioné y usé tres. Cada uno con sus resultados.
Antes de pasar a todos los detalles sobre el acrobot, hay que hablar sobre el estado de Julia. Para este ejercicio preferí usar Python 3, donde existe un único Gym y un único Keras. En Julia, hay al menos 3 wrappers distintos para cada librería exclusiva de Python. No todos están registrados como paquetes oficiales, y todavía peor, no todos funcionan. Después de intentar usar dos wrappers para Gym sin éxito, mejor moví todo a Python, donde funcionó en cinco minutos con todos los requisitos que tenía.
Después de ponernos en la misma página respecto al lenguaje, es hora de ver como usar Gym para entrenar una computadora. Aunque mi implemenntación no es la mejor manera. No soy un experto.
Todos los scripts que usé están en este repositorio.
Acrobot
El acrobot es un pequeño juguete con dos brazos y un torque en la conexión de estos. La idea es maniobrar el torque para que el brazo inferior alcance una cierta altura, como en la animación de abajo.

Para poder simular al acrobot, hace falta programar unas ecuaciones diferenciales, pero afortunadamente, la librería Gym de OpenAI ya lo tiene cubierto. Hasta permite grabar videos del comportamiento de los agentes.
Si tenemos una mitad hecha, falta hacer la otra mitad. Para esto, volvemos a unas ideas anteriores:
- Políticas $ \epsilon $-greedy
- Discretizar el espacio de estados
Aunque la última vez dije que usaría tile-coding para entrenar, al final no lo implementé, y mejor discreticé sencillamente el espacio de estados. Creé intervalos del -1 al 1 donde todos los números que estuvieran en medio caerían en los mismos lugares. Así, reduje el espacio de estados de una infinidad a la 6, a alrededor de 50000, 18000, y 12000. Que siguen siendo bastantes.
La mayor parte de las animaciones solo son pedazos del episodio completo, debido a los límites del convertidor de mp4 a gif. El acrobot tiene 500 pasos para completar su tarea. A menos que mencione que el acrobot tuvo éxito, las animaciones que puedes ver son de 10 a 20 de 32 segundos de desesperación.
Acrobot con Q-Learning
Para empezar, probé con algo muy sencillo: Q-Learning. En pocas líneas de código queda el algoritmo junto con la discretización del estado. Al principio fueron tantas entradas en el diccionario de valores-acción que se acabó la memoria asignada a Python y el programa abortó. Así que 50000 estados sigue siendo impensable. Luego de aumentar los intervalos, logré reducir la cardinalidad a alrededor de 18000 estados. Lo que solucionó el problema anterior.
Después de 30000 episodios de entrenamiento, el agente logra terminar la tarea a tiempo seguido, pero no siempre. El tiempo que se toma es variable. Para que veas, fíjate en la siguiente animación del primer episodio.

Muchas veces, el acrobot solo se balancea de un lado a otro, sin realmente acercarse a la línea de arriba. Sin embargo, otra veces sucede algo como lo que pasó en el episodio 29000:
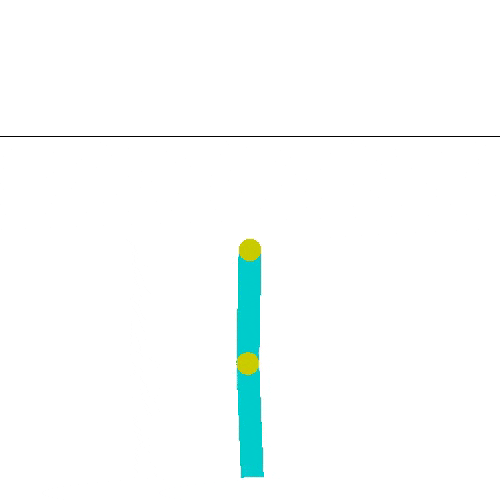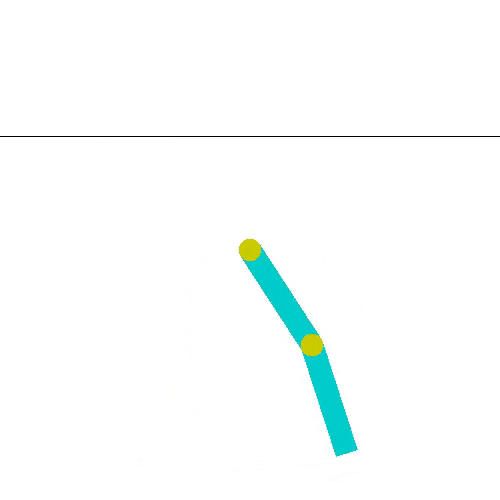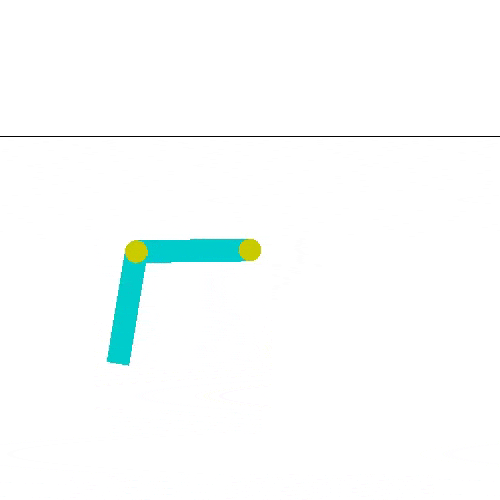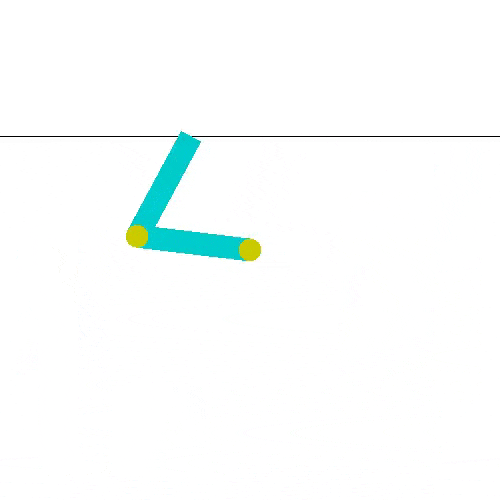
El acrobot hace el helicóptero, logra impulsarse, y alcanza la meta.
Aunque el agente no aprendió a resolver el problema consistentemente, si aprendió
a que necesita conseguir impulso rápidamente. Esto se puede deber a los parámetros
que usé, así como a la discretización del espacio que programé. Si quieres correr
a este amigo, el código está en el módulo acrobot_qlearning.py. Los parámetros
que usé fueron los siguientes:
episode_count = 30000
step_size = 0.3
discount = 0.9
epsilon = 0.1
interval_range = 0.75
Acrobot con doble Q-Learning
Si te gustó el Q-Learning, ¿qué tal si metemos dos Q? Y eso es doble Q-Learning. Simplemente usa dos funciones de acción-valor que se van actualizando de manera dependiente. El algoritmo que viene en el artículo original es este:
Construir Q_A, Q_B, s
Repetir
Escoger a basado en Q_A(s, *) + Q_B(s, *), observar r, s'
Escoger aleatoriamente si se actualiza Q_A o Q_B
Si se actualiza Q_A entonces
Definir a* = arg max_a Q_A(s', a)
Q_A(s, a) = Q_A(s, a) + alpha(r + gamma Q_B(s', a*) - Q_A(s, a))
En caso contrario
Definir a* = arg max_a Q_B(s', a)
Q_B(s, a) = Q_B(s, a) + alpha(r + gamma Q_A(s', a*) - Q_B(s, a))
Fin si
s = s'
Hasta final
Es decir: tienes dos estimadores, los usas en conjunto para elegir una acción, y luego actualizas cualquiera de los dos usando el valor del otro. Según el autor, esto ayuda a evitar sobreestimaciones del valor real de la función acción-valor. Una cosa solamente: está pensado para usarse con entornos estocásticos. Hay que tener eso en cuenta.
El código es muy parecido al del módulo anterior, solo tuve que cambiar alrededor de 6 líneas de código. Las parámetros que usé fueron:
episode_count = 41001
step_size = 0.3
discount = 0.9
epsilon = 0.1
interval_range = 1.0
Al principio obtuve esto:

Después de 29000 episodios podemos ver como este agente también aprende a hacer el helicóptero.

A los 38000 podemos ver que si llega a la línea. Como en el caso anterior, el agente resuelve el problema seguido, pero no siempre. Esto lo podemos ver con el resultado en el episodio 41000.
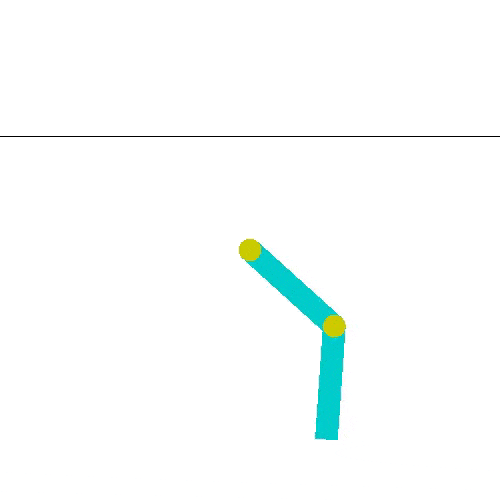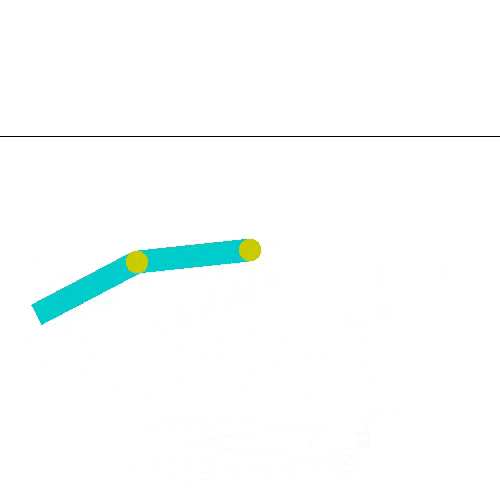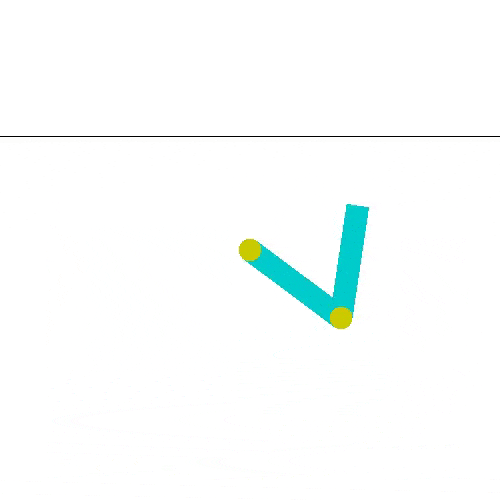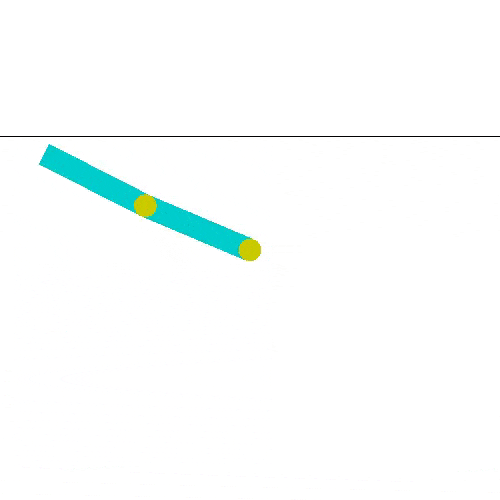
Si quieres ejecutar este caso, el script que buscas es acrobot_doubleqlearning.py. Aquí también sería bueno cambiar los parámetros para
ver si aprende mejor.
Acrobot con Deep Q-Learning
Por último, veamos que sale si usamos redes neuronales profundas, por que está de moda. Y porque entonces no ocupamos preocuparnos por la discretización del espacio. A diferencia de los otros algoritmos que fueron entrenados con miles y miles de episodios, este agente solo fue entrenado con 600. No tengo una supercomputadora en mi casa.
La idea del Deep Q-Learning es usar una red neuronal profunda para aproximar la función de acción-valor, en vez de utilizar una tabla o un diccionario. Además, se ajusta la predicción en cada iteración a través de la repetición de iteraciones pasadas. Para más detalles puedes leer el artículo original.
En pocas palabras, este algoritmo es muy bueno, muy lento, y muy sencillo, si usas
Keras para enmascarar todo el código para crear una red neuronal. Siguiendo la
nomenclatura, el código que obtuvo los siguientes resultados está en el módulo
acrobot_deepqlearning.py.
Los parámetros que usé durante los primeros 200 episodios fueron estos:
self.gamma = 0.9
self.epsilon = 0.1
self.learning_rate = 0.05
Para los otros 400 episodios fueron estos:
self.gamma = 0.9
self.epsilon = 0.15
self.learning_rate = 0.08
Si sabes de redes neuronales probablemente quieres decirme lo horriblemente mal que implementé el algoritmo. Si es así, por favor mándame un correo para arreglar el código, seguro queda un agente superhumano.
En el inicio, el agente se comporta como los otro métodos.
Durante el entrenamiento a veces ganaba, aunque tampoco fue muy constante. A este se lo nota que le falta mucho más entrenamiento, aunque lo haya puesto por 6 horas reales. Al menos parece que aprendió a impulsarse mejor.

Lo bueno de toda esta experimentación es que muestra lo fácil y rápido que es implementar un algoritmo distinto de aprendizaje por refuerzo. Si tienes el entorno programado para funcionar tan transparentemente como en Gym, todo es más fácil.